Article
【python 爬虫实战】批量爬取站长之家的图片
- 2/27/2020
概述:
站长之家的图片爬取
使用BeautifulSoup解析 html
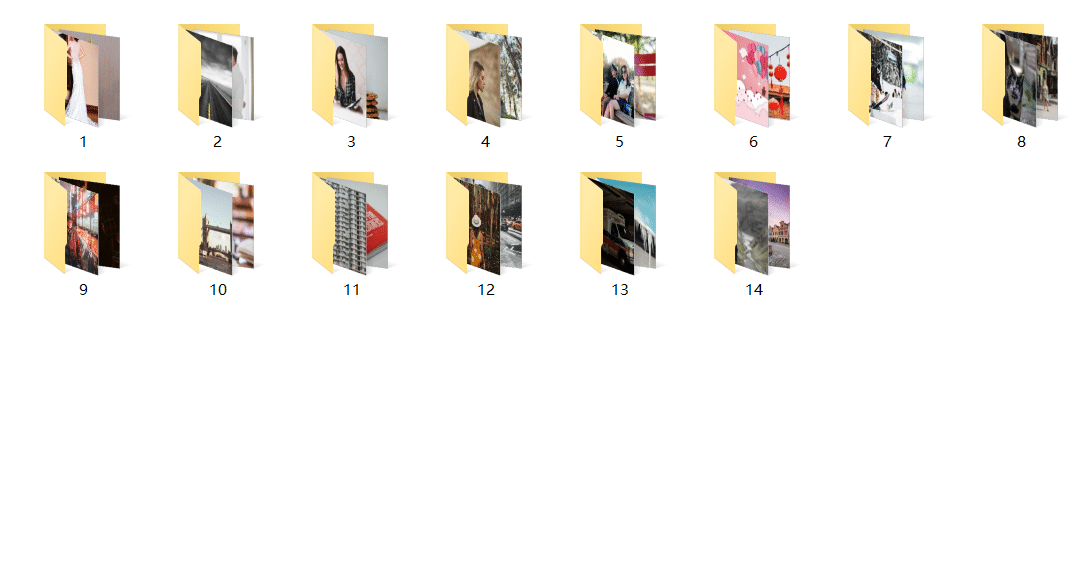
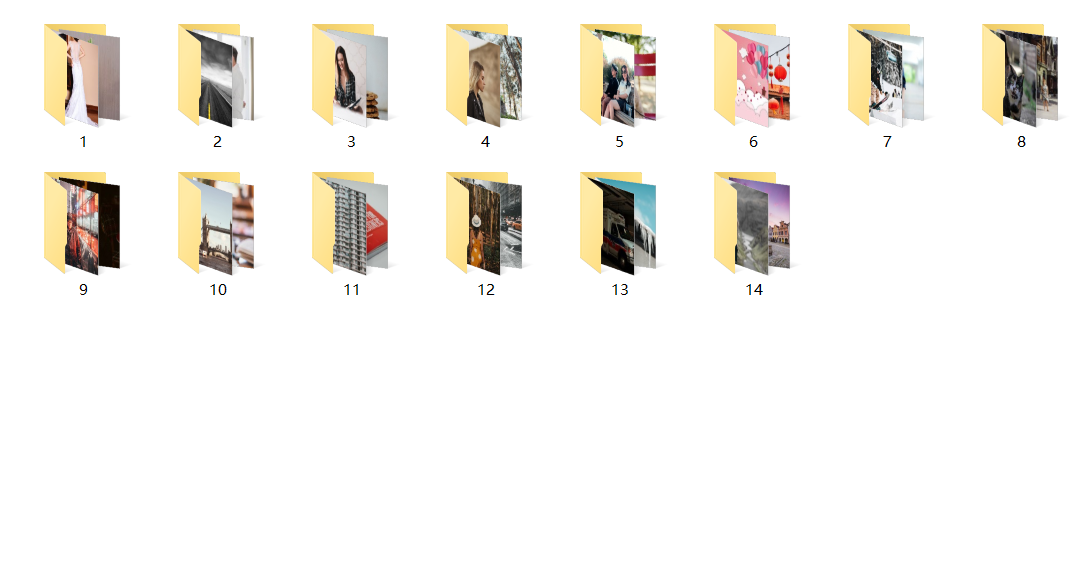
通过浏览器的形式来爬取,爬取成功后以二进制保存,保存的时候根据每一页按页存放每一页的图片
第一页:http://sc.chinaz.com/tupian/index.html 🔗 第二页:http://sc.chinaz.com/tupian/index_2.html 🔗 第三页:http://sc.chinaz.com/tupian/index_3.html 🔗 以此类推,遍历 20 页
源代码
# @Author: lomtom
# @Date: 2020/2/27 14:22
# @email: lomtom@lomtom.cn
# 站长之家的图片爬取
# 使用BeautifulSoup解析html
# 通过浏览器的形式来爬取,爬取成功后以二进制保存
# 第一页:http://sc.chinaz.com/tupian/index.html
# 第二页:http://sc.chinaz.com/tupian/index_2.html
# 第三页:http://sc.chinaz.com/tupian/index_3.html
# 遍历14页
import os
import requests
from bs4 import BeautifulSoup
def getImage():
url = ""
for i in range(1,15):
# 创建文件夹,每一页放进各自的文件夹
download = "images/%d/"%i
if not os.path.exists(download):
os.mkdir(download)
# url
if i ==1:
url = "http://sc.chinaz.com/tupian/index.html"
else:
url = "http://sc.chinaz.com/tupian/index_%d.html"%i
#发送请求获取响应,成功状态码为200
response = requests.get(url)
if response.status_code == 200:
# 使用bs解析网页
bs = BeautifulSoup(response.content,"html5lib")
# 定位到图片的div
warp = bs.find("div",attrs={"id":"container"})
# 获取img
imglist = warp.find_all_next("img")
for img in imglist:
# 获取图片名称和链接
title = img["alt"]
src = img["src2"]
# 存入文件
with open(download+title+".jpg","wb") as file:
file.write(requests.get(src).content)
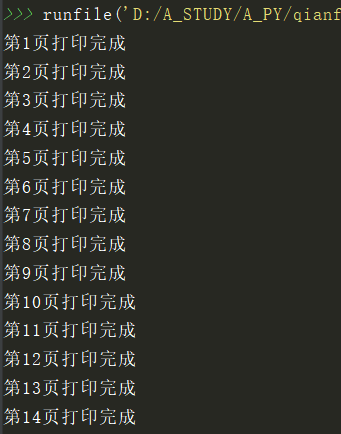
print("第%d页打印完成"%i)
if __name__ == '__main__':
getImage()
效果图
作者
Copyright
本文为原创内容,欢迎分享与引用,请保留作者与原文链接。